
KotlinコードをNativeコード(C/C++)に置き換えることで処理の高速化が期待できます。さらに高速化するにはマルチスレッド化が有効です。マルチコアCPUの能力を最大限に活用するのです。
このNativeコードをマルチスレッド化する手段にOpenMPがあります。
今回、画像処理を行う中でNativeコードを高速化する必要性が発生し、OpenMPを調査しました。
その成果として、Android NDKでOpenMPを使う方法とOpenMPプログラミングについて紹介します。
OpenMPとは
OpenMPはマルチスレッド(並列)プログラミングを行うために標準化されたAPIです。
図のような「共有メモリ+マルチスレッド型」のコンピュータ向けです。
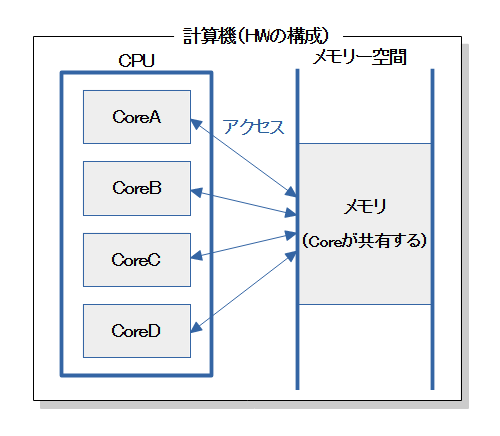
現在、世の中に出回っているCPUの多くはマルチコアなので、ほとんどのパソコンやAndroid端末が当てはまります。
また、OpenMPはスケーラブル(プロセッサ数に合わせて並列化数が変わる)なので多様なコア数のCPUに対応でき、標準化もされていることから、移植性の高いプログラミングができる利点を持っています。
※OpenMPの詳細は「OpenMP」を参照してください。
OpenMPの有効化
OpenMPを使うにはコンパイラが対応している必要があります。
NDKビルドシステムのC/C++コンパイラはOpenMPに対応しています。ただし、使うために設定が必要です。
※NDK(Ver 21.16352462)はOpenMP Ver5.0(最新版はVer5.1)をサポートしています。
有効化フラグの指定
コンパイラはデフォルトでOpenMPが無効になっています。有効化が必要です。
有効化するにはコンパイラのオプションでフラグ(-fopenmp)を指定します。
# Sets the minimum version of CMake required to build the native library.
cmake_minimum_required(VERSION 3.10.2)
# Declares and names the project.
project("openmp")
find_library( log-lib log )
set (CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fopenmp")
add_library( native-lib SHARED native-lib.cpp )
target_link_libraries( native-lib ${log-lib} -static-openmp)
ライブラリのリンク
OpenMPライブラリのリンクが必要です。
コンパイラはライブラリ名を指定しなくても自動でリンクしてくれるようです。ただし、Staticリンクで行います。Staticリンクの指定(-static-openmp)をオプションで与えます。
# Sets the minimum version of CMake required to build the native library.
cmake_minimum_required(VERSION 3.10.2)
# Declares and names the project.
project("openmp")
find_library( log-lib log )
set (CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fopenmp")
add_library( native-lib SHARED native-lib.cpp )
target_link_libraries( native-lib ${log-lib} -static-openmp)
Staticリンクはアプリのパッケージ内にライブラリを含めてしまうリンク方法です。Dynamicリンクのように、実行時にストレージからメモリー上へライブラリーを読み込む作業が発生しません。
よって、Staticリンクは起動が早い反面、アプリのサイズが大きくなります。
ちなみに、調べてみたところAndroid端末内にOpenMPのライブラリは実装されていませんでした。なので、Staticリンクでアプリのパッケージ内に含めて配布するしかなく、Dynamicリンクは出来ないようです。
ヘッダの指定
後述するOpenMPのランタイム関数を使う場合はソースコードにヘッダの指定が必要です。
ここに、関数のプロトタイプや定数、構造体が書かれています。
#include <jni.h>
#include <string>
#include <android/log.h>
#include <omp.h>
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_openmp_MainActivity_openmpSample(
JNIEnv* env,
jobject /* this */) {
:
}
OpenMPの記述
pragma(プラグマ)
マルチスレッド化の記述はpragmaを使って行います。
pragmaはソースコードからコンパイラに対して指示を出す構文です。
この指示に従ってコンパイラはマルチスレッド化を行う場所と方法を認識します。
#pragma omp directive-name [clause[ [,] clause] ... ]
構文は「#pragma omp」で始まり、「命令、宣言、宣言、…」が続き、終わりは改行です。
コンパイラがOpenMPに対応していない場合やOpenMPが有効になっていない場合、pragmaは無視される仕組みになっています。
ランタイム関数
pragmaで行うマルチスレッド化の指示以外にランタイム関数が使えます。
よく使う関数の一例です。
| カテゴリ | 関数名 | 機能 |
|---|---|---|
| 実行環境ルーチン | omp_get_max_threads() | 利用可能な最大スレッド数を返す |
| omp_get_thread_num() | タスクを実行しているスレッド番号を返す |
マルチスレッド化(並列化)
parallel(同じタスクの並列化)
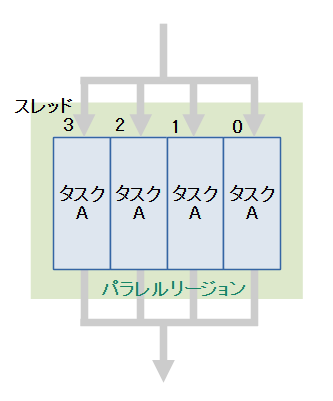
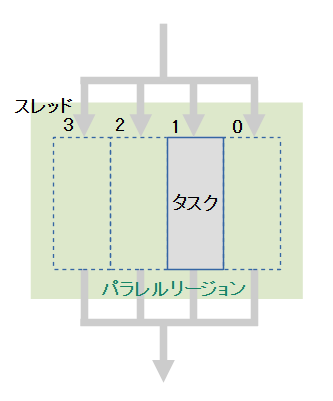
parallelは同じタスクを並列に処理します。
図に示すように各スレッドは同じタスクを処理しているので、parallel単体ではマルチスレッド化の利点はありません。後述するsectionsやforと組み合わせた時に効力を発揮します。
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "Total thread = %d", omp_get_max_threads());
#pragma omp parallel
{
for(int i = 0; i < 3; i++){
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
}
}
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (0) i = 0 .../com.example.nativecode.openmp I/openmpSample: (0) i = 1 .../com.example.nativecode.openmp I/openmpSample: (0) i = 2 .../com.example.nativecode.openmp I/openmpSample: (2) i = 0 .../com.example.nativecode.openmp I/openmpSample: (2) i = 1 .../com.example.nativecode.openmp I/openmpSample: (2) i = 2 .../com.example.nativecode.openmp I/openmpSample: (1) i = 0 .../com.example.nativecode.openmp I/openmpSample: (1) i = 1 .../com.example.nativecode.openmp I/openmpSample: (1) i = 2 .../com.example.nativecode.openmp I/openmpSample: (3) i = 0 .../com.example.nativecode.openmp I/openmpSample: (3) i = 1 .../com.example.nativecode.openmp I/openmpSample: (3) i = 2
parallelはマルチスレッド化の最も基本となる命令です。
「#pragma omp parallel」に続くブロック({ }に挟まれた部分)または命令文がマルチスレッド化されるタスクになります。このマルチスレッド化される領域をパラレルリージョンと呼びます。

sections(異なるタスクの並列化)
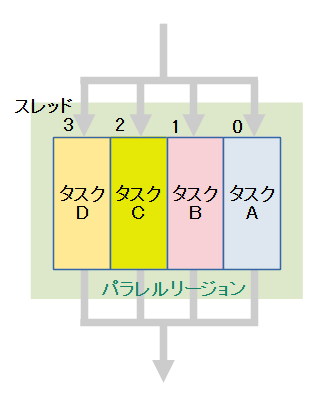
sectionsは異なるタスクを並列に処理します。
parallelによって起動された各々のスレッドへ、sectionで定義されたタスクを割り当てる動作になります。
「section数>利用可能な最大スレッド数」の場合は、最大スレッド数で並列に処理を開始し、処理の終わったスレッドが残りのsectionを処理していきます。処理の順番は記述の上から下に向かって行われます。
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "Total thread = %d", omp_get_max_threads());
#pragma omp parallel
{
#pragma omp sections
{
#pragma omp section // タスクA:0~2の範囲を処理
{
for(int i = 0; i < 3; i++){
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
}
}
#pragma omp section // タスクB:3~5の範囲を処理
{
for(int i = 3; i < 6; i++){
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
}
}
#pragma omp section // タスクC:5~8の範囲を処理
{
for(int i = 6; i < 9; i++){
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
}
}
#pragma omp section // タスクD:9~11の範囲を処理
{
for(int i = 9; i < 12; i++){
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
}
}
}
}
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (0) i = 0 .../com.example.nativecode.openmp I/openmpSample: (0) i = 1 .../com.example.nativecode.openmp I/openmpSample: (0) i = 2 .../com.example.nativecode.openmp I/openmpSample: (3) i = 9 .../com.example.nativecode.openmp I/openmpSample: (3) i = 10 .../com.example.nativecode.openmp I/openmpSample: (3) i = 11 .../com.example.nativecode.openmp I/openmpSample: (1) i = 3 .../com.example.nativecode.openmp I/openmpSample: (1) i = 4 .../com.example.nativecode.openmp I/openmpSample: (1) i = 5 .../com.example.nativecode.openmp I/openmpSample: (2) i = 6 .../com.example.nativecode.openmp I/openmpSample: (2) i = 7 .../com.example.nativecode.openmp I/openmpSample: (2) i = 8
for(Forループを分割して並列化)
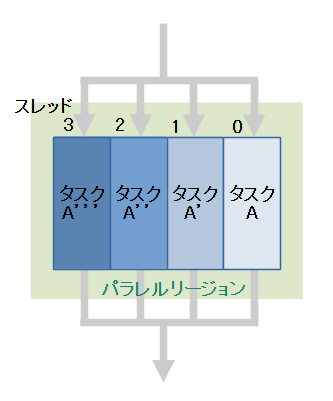
forはループ分割して並列に処理します。
parallelによって起動された各々のスレッドへ、分割されたループを割り当てる動作になります。
例えば、ループを4つに分割する場合は次のようになります。
i = 0~2
i = 0~11 ---> i = 3~5 ... 処理の重みが均等になるように分割
i = 6~8
i = 9~11
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "Total thread = %d", omp_get_max_threads());
#pragma omp parallel
{
#pragma omp for
for(int i = 0; i < 12; i++){
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
}
}
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (0) i = 0 .../com.example.nativecode.openmp I/openmpSample: (0) i = 1 .../com.example.nativecode.openmp I/openmpSample: (0) i = 2 .../com.example.nativecode.openmp I/openmpSample: (2) i = 6 .../com.example.nativecode.openmp I/openmpSample: (2) i = 7 .../com.example.nativecode.openmp I/openmpSample: (2) i = 8 .../com.example.nativecode.openmp I/openmpSample: (3) i = 9 .../com.example.nativecode.openmp I/openmpSample: (3) i = 10 .../com.example.nativecode.openmp I/openmpSample: (3) i = 11 .../com.example.nativecode.openmp I/openmpSample: (1) i = 3 .../com.example.nativecode.openmp I/openmpSample: (1) i = 4 .../com.example.nativecode.openmp I/openmpSample: (1) i = 5
single(単一のスレッドで処理)
singleは単一のスレッドで処理します。
parallelによって起動されたスレッドの一つへ、singleで定義されたタスクを割り当てる動作になります。
タスクが割り当てられなかったスレッドは休止します。
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "Total thread = %d", omp_get_max_threads());
#pragma omp parallel
{
__android_log_print(ANDROID_LOG_INFO, // <-- すべてのスレッドで実行
"openmpSample", "(%d) Running!", omp_get_thread_num());
#pragma omp single
{
for(int i = 0; i < 12; i++){
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
}
}
}
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (1) Running! .../com.example.nativecode.openmp I/openmpSample: (1) i = 0 .../com.example.nativecode.openmp I/openmpSample: (1) i = 1 .../com.example.nativecode.openmp I/openmpSample: (1) i = 2 .../com.example.nativecode.openmp I/openmpSample: (1) i = 3 .../com.example.nativecode.openmp I/openmpSample: (2) Running! .../com.example.nativecode.openmp I/openmpSample: (1) i = 4 .../com.example.nativecode.openmp I/openmpSample: (1) i = 5 .../com.example.nativecode.openmp I/openmpSample: (1) i = 6 .../com.example.nativecode.openmp I/openmpSample: (1) i = 7 .../com.example.nativecode.openmp I/openmpSample: (1) i = 8 .../com.example.nativecode.openmp I/openmpSample: (1) i = 9 .../com.example.nativecode.openmp I/openmpSample: (1) i = 10 .../com.example.nativecode.openmp I/openmpSample: (1) i = 11 .../com.example.nativecode.openmp I/openmpSample: (0) Running! .../com.example.nativecode.openmp I/openmpSample: (3) Running!
parallel for
parallelとforをまとめたものです。parallelの入れ子でforを書いた場合と同等です。
#pragma omp parallel for
for(int i = 0; i < 12; i++){
...
}
#pragma omp parallel
{
#pragma omp for
for(int i = 0; i < 12; i++){
...
}
}
parallel sections
parallelとsectionsをまとめたものです。parallelの入れ子でsectionを書いた場合と同等です。
#pragma omp parallel sections
{
#pragma omp section
{
...
}
#pragma omp section
{
...
#pragma omp section
{
...
}
#pragma omp section
{
...
}
}
#pragma omp parallel
{
#pragma omp sections
{
#pragma omp section
{
...
}
#pragma omp section
{
...
#pragma omp section
{
...
}
#pragma omp section
{
...
}
}
}
共有変数とプライベート変数
マルチスレッド(並列)化された各々のスレッドからパラレルリージョン内の変数へアクセスするとき、扱われ方の違いよって変数は2つのタイプに分けられます。共有変数とプライベート変数です。
両者の違いとデフォルト
共有変数とプライベート変数の違いは図のようになります。
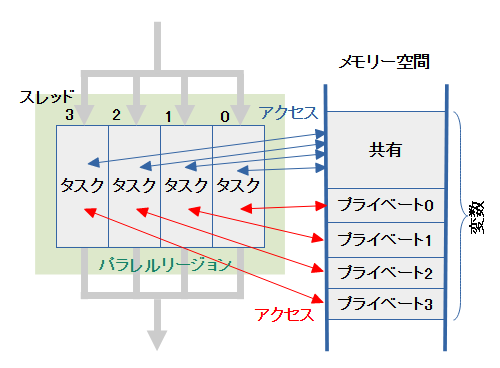
例えばスレッド1の変更はスレッド2に影響します。逆にスレッド2の変更はスレッド1に影響します。
共有変数はC/C++言語仕様に従って初期化(初期値の指定が無ければ0または0.0)されます。
プライベート変数 とは、各々のスレッドが独立に持つ変数です。例えばスレッド1の変更はスレッド2に影響しません。逆にスレッド2の変更はスレッド1に影響しません。
プライベート変数はパラレルリージョン内で初期化されないので注意してください。初期化する記述が必要になります。
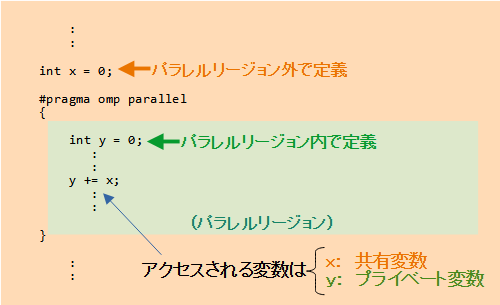
デフォルトで、パラレルリージョン内で宣言された変数はプライベート変数になり、パラレルリージョン外で宣言された変数は共有変数になります。
| 定義場所 | デフォルトのタイプ | 成れるタイプ |
|---|---|---|
| リージョン外で定義 | 共有変数 | 共有変数 プライベート変数 |
| リージョン内で定義 | プライベート変数 | プライベート変数 |
ただし、パラレルリージョン外で宣言された変数はプライベート変数にも成れます。変更方法は後述します。
逆にパラレルリージョン内で宣言された変数はプライベート変数以外に成れません。
デフォルトからの変更
パラレルリージョン内の変数はデフォルトで共有変数とプライベート変数のどちらかになります。
次の宣言を与えるとデフォルトから指定したタイプへ変更できます。
private(プライベート変数へ変更)
パラレルリージョン内の共有変数をプライベート変数として扱うように変更します。
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "Total thread = %d", omp_get_max_threads());
int value = 10;
#pragma omp parallel private(value)
{
value = 0; // プライベート変数の初期化
value += omp_get_thread_num();
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) Value = %2d", omp_get_thread_num(), value);
}
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", " Value = %2d", value);
変数valueはスレッドが独立して持つ変数になるので、リージョン外のvalueとは別物です。リージョン外で行った初期化は活きません。リージョン内で初期化が必要になります。
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (0) Value = 0 .../com.example.nativecode.openmp I/openmpSample: (1) Value = 1 .../com.example.nativecode.openmp I/openmpSample: (2) Value = 2 .../com.example.nativecode.openmp I/openmpSample: (3) Value = 3 .../com.example.nativecode.openmp I/openmpSample: Value = 10
ちなみに、リージョン内で初期化を行わなかった(「value = 0;」をコメントアウト)場合、以下のようにランダムな値になってしまいます。
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (0) Value = -1490964480 .../com.example.nativecode.openmp I/openmpSample: (1) Value = -1478293054 .../com.example.nativecode.openmp I/openmpSample: (2) Value = -1478293053 .../com.example.nativecode.openmp I/openmpSample: (3) Value = 3 .../com.example.nativecode.openmp I/openmpSample: Value = 10
パラレルリージョン内のプライベート変数は共有変数に変更することは出来ません。
なぜなら、デフォルトでプライベートになった変数はプライベート変数以外に成れないからです。
従って、sharedは単体で使えません。後述するdefault(none)と併せて使います。
default(none)(デフォルトの無効化)
パラレルリージョン内の変数のタイプを無効化します。
パラレルリージョン内で宣言された変数はプライベート変数以外に成れないので、無効化したとしてもプライベート変数のままです。
しかし、パラレルリージョン外で定義された変数は、共有変数として扱うのか、プライベート変数として扱うのか、不明になります。
不明のままではコンパイル出来ない(エラーになる)ので、default(none)を指定したときは、それに続いてprivateまはたshared宣言を使って明確にします。
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "Total thread = %d", omp_get_max_threads());
int value = 10;
// #pragma omp parallel default(none) // エラーになる
// #pragma omp parallel default(none),private(value) // プライベート変数で扱う
#pragma omp parallel default(none),shared(value) // 共有変数で扱う
{
int num = omp_get_thread_num();
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) Value = %2d",
omp_get_thread_num(), value + num);
}
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", " Value = %2d", value);
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (0) Value = 10 .../com.example.nativecode.openmp I/openmpSample: (3) Value = 13 .../com.example.nativecode.openmp I/openmpSample: (1) Value = 11 .../com.example.nativecode.openmp I/openmpSample: (2) Value = 12 .../com.example.nativecode.openmp I/openmpSample: Value = 10
ちなみに…
上記のサンプルはdefault(none)が無くても結果は同じです。
:
#pragma omp parallel
{
...
}
:
しかし、Android Studioから注意されます。
OpenMP directive `parallel` does not specify `default` clause, consider specifying `default(none)` clause. ----- OpenMPの命令`parallel`は` default`句を指定していません。`default(none) `句を指定することを検討してください。
Android Studioはdefault(none)の使用が推奨されるようです。
共有変数とプライベート変数の扱いを取り違えても、コンパイルは通ります。しかし、マルチスレッド化したタスクは期待通りの動作になるとは限りません。
暗黙(デフォルト)で使うよりも、プログラムに明示(default(none)で明示を強要)することで、プログラマに注意を施す狙いがあると思われます。
firstprivate(元の変数の値で初期化)
パラレルリージョン内の共有変数をプライベート変数として扱うように変更すると共に、元の変数の値で初期化します。
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "Total thread = %d", omp_get_max_threads());
int value = 10;
#pragma omp parallel firstprivate(value)
{
// value = 0;
value += omp_get_thread_num(); // 元の変数(value)の値(10)で初期化
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) Value = %2d", omp_get_thread_num(), value);
}
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", " Value = %2d", value);
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (2) Value = 12 .../com.example.nativecode.openmp I/openmpSample: (1) Value = 11 .../com.example.nativecode.openmp I/openmpSample: (0) Value = 10 .../com.example.nativecode.openmp I/openmpSample: (3) Value = 13 .../com.example.nativecode.openmp I/openmpSample: Value = 10
lastprivate(元の変数へ値を書き戻す)
パラレルリージョン内の共有変数をプライベート変数として扱うように変更すると共に、元の変数へ結果を書き戻します。
forやsectionsで使用可能です。
【forの場合】
forの場合はカウンタ変数(下記の例のi)の最後の値(下記の例の場合 3)を処理したスレッドの結果が書き戻されます。
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "Total thread = %d", omp_get_max_threads());
int value = 10;
#pragma omp parallel for lastprivate(value)
for(int i = 0; i < 4; i++){
value = 100;
value += omp_get_thread_num();
__android_log_print(ANDROID_LOG_INFO, "openmpSample",
"(%d) Value = %2d i = %d", omp_get_thread_num(), value, i);
}
__android_log_print(ANDROID_LOG_INFO, "openmpSample",
" Value = %2d", value);
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (1) Value = 101 i = 1 .../com.example.nativecode.openmp I/openmpSample: (0) Value = 100 i = 0 .../com.example.nativecode.openmp I/openmpSample: (2) Value = 102 i = 2 .../com.example.nativecode.openmp I/openmpSample: (3) Value = 103 i = 3 .../com.example.nativecode.openmp I/openmpSample: Value = 103
【sectionsの場合】
sectionsの場合は最後(一番下)のsectionが投入されたスレッドの結果が書き戻されます。
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "Total thread = %d", omp_get_max_threads());
int value = 10;
#pragma omp parallel sections lastprivate(value)
{
#pragma omp section
{
value = 100;
value += omp_get_thread_num();
__android_log_print(ANDROID_LOG_INFO, "openmpSample",
"(%d) Value = %2d", omp_get_thread_num(), value);
}
#pragma omp section
{
value = 100;
value += omp_get_thread_num();
__android_log_print(ANDROID_LOG_INFO, "openmpSample",
"(%d) Value = %2d", omp_get_thread_num(), value);
}
#pragma omp section
{
value = 100;
value += omp_get_thread_num();
__android_log_print(ANDROID_LOG_INFO, "openmpSample",
"(%d) Value = %2d", omp_get_thread_num(), value);
}
#pragma omp section
{
value = 100;
value += omp_get_thread_num();
__android_log_print(ANDROID_LOG_INFO, "openmpSample",
"(%d) Value = %2d", omp_get_thread_num(), value);
}
}
__android_log_print(ANDROID_LOG_INFO, "openmpSample",
" Value = %2d", value);
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (0) Value = 100 .../com.example.nativecode.openmp I/openmpSample: (2) Value = 102 .../com.example.nativecode.openmp I/openmpSample: (1) Value = 101 .../com.example.nativecode.openmp I/openmpSample: (3) Value = 103 .../com.example.nativecode.openmp I/openmpSample: Value = 103
処理の同期
タスク間の同期
並列に処理されるタスクは同じ内容だったとしてもスレッド毎に進捗がまちまちになります。スレッドに割り当てられるCPUリソース(使える時間・時刻)が時々で異なるためです。
マルチスレッドプログラミングを行っていると、「タスクABCDの結果をタスクEで処理する」といった逐次処理が出てきます。タスクABCDの進捗がまちまちだと、Aが終わる前にEの処理が始まって、間違った結果となる場面が発生してしまいます。
そのような場面でタスク間の同期が必要になります。
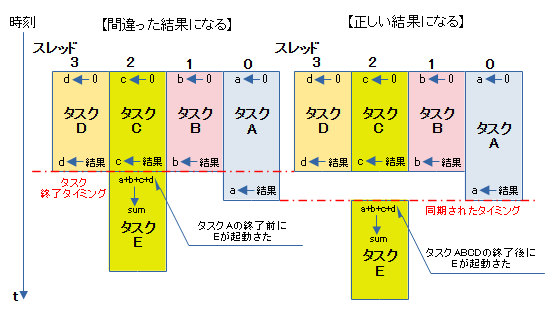
マルチスレッドプログラミングを行うときは、常に同期の取り方を考慮しなければ、正しい結果はえられません。
同期される・されない
sections・for・singleは対象となるタスクの処理が終わるまで、すべてのスレッドの進行がブロックされます。なので、sections、for、single以降の処理は同期してスタートします。
逆に、parallelのみの場合はブロックされません。parallel以降の処理はばらばらなタイミングでスタートします。
#pragma omp parallel
{
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) Task", omp_get_thread_num());
// --- ここで同期されない ---
__android_log_print(ANDROID_LOG_INFO, // <-- すべてのスレッドで実行
"openmpSample", "(%d) Finished!", omp_get_thread_num());
}
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (1) Task .../com.example.nativecode.openmp I/openmpSample: (2) Task .../com.example.nativecode.openmp I/openmpSample: (2) Finished! .../com.example.nativecode.openmp I/openmpSample: (1) Finished! .../com.example.nativecode.openmp I/openmpSample: (3) Task .../com.example.nativecode.openmp I/openmpSample: (3) Finished! .../com.example.nativecode.openmp I/openmpSample: (0) Task .../com.example.nativecode.openmp I/openmpSample: (0) Finished!
#pragma omp parallel
{
#pragma omp sections
{
#pragma omp section
{
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) Task A", omp_get_thread_num());
}
#pragma omp section
{
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) Task B", omp_get_thread_num());
}
#pragma omp section
{
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) Task C", omp_get_thread_num());
}
#pragma omp section
{
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) Task D", omp_get_thread_num());
}
}
// --- ここで同期される ---
__android_log_print(ANDROID_LOG_INFO, // <-- すべてのスレッドで実行
"openmpSample", "(%d) Finished!", omp_get_thread_num());
}
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (2) Task C .../com.example.nativecode.openmp I/openmpSample: (1) Task B .../com.example.nativecode.openmp I/openmpSample: (0) Task A .../com.example.nativecode.openmp I/openmpSample: (3) Task D .../com.example.nativecode.openmp I/openmpSample: (0) Finished! .../com.example.nativecode.openmp I/openmpSample: (2) Finished! .../com.example.nativecode.openmp I/openmpSample: (3) Finished! .../com.example.nativecode.openmp I/openmpSample: (1) Finished!
#pragma omp parallel
{
#pragma omp for
for(int i = 0; i < 4; i++){
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
}
// --- ここで同期される ---
__android_log_print(ANDROID_LOG_INFO, // <-- すべてのスレッドで実行
"openmpSample", "(%d) Finished!", omp_get_thread_num());
}
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (0) i = 0 .../com.example.nativecode.openmp I/openmpSample: (2) i = 2 .../com.example.nativecode.openmp I/openmpSample: (3) i = 3 .../com.example.nativecode.openmp I/openmpSample: (1) i = 1 .../com.example.nativecode.openmp I/openmpSample: (1) Finished! .../com.example.nativecode.openmp I/openmpSample: (2) Finished! .../com.example.nativecode.openmp I/openmpSample: (0) Finished! .../com.example.nativecode.openmp I/openmpSample: (3) Finished!
#pragma omp parallel
{
#pragma omp single
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) Task", omp_get_thread_num());
// --- ここで同期される ---
__android_log_print(ANDROID_LOG_INFO, // <-- すべてのスレッドで実行
"openmpSample", "(%d) Finished!", omp_get_thread_num());
}
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (2) Task .../com.example.nativecode.openmp I/openmpSample: (2) Finished! .../com.example.nativecode.openmp I/openmpSample: (3) Finished! .../com.example.nativecode.openmp I/openmpSample: (0) Finished! .../com.example.nativecode.openmp I/openmpSample: (1) Finished!
barrier
スレッドの処理がbarrierの位置に到達すると、すべてのスレッドの進行はブロックされます。なので、barrier以降の処理は同期してスタートします。
#pragma omp parallel
{
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) Task", omp_get_thread_num());
#pragma omp barrier
// --- ここで同期される ---
__android_log_print(ANDROID_LOG_INFO, // <-- すべてのスレッドで実行
"openmpSample", "(%d) Finished!", omp_get_thread_num());
}
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (0) Task .../com.example.nativecode.openmp I/openmpSample: (1) Task .../com.example.nativecode.openmp I/openmpSample: (3) Task .../com.example.nativecode.openmp I/openmpSample: (2) Task .../com.example.nativecode.openmp I/openmpSample: (0) Finished! .../com.example.nativecode.openmp I/openmpSample: (2) Finished! .../com.example.nativecode.openmp I/openmpSample: (3) Finished! .../com.example.nativecode.openmp I/openmpSample: (1) Finished!
共有変数のアクセスの同期(アトミック処理)
共有変数の値を+1するタスクAとBが並列に処理されていたとします。
その時、タスクBの処理中にタスクAの処理が割り込むと、タスクBの結果をタスクAの結果で上書きしてしまいます。タスクBの処理は無視されたことになり、最終的に間違った結果が得られます。
このような状態をアクセスの競合といいます。
これを回避するために、「タスクBが変数へアクセスしている時はタスクAのアクセスをブロック」し、「タスクBのアクセスが終わったらタスクAのアクセスを許す」といった処理が必要になります。
つまり、共有変数のアクセスの同期をとるということです。
このような処理形態をアトミック処理といいます。
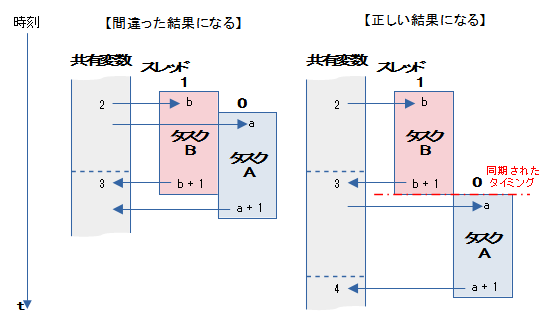
マルチスレッドプログラミングを行うときは、常に同期の取り方を考慮しなければ、正しい結果はえられません。
以下に上げるcritical・atomic・reductionはどれも共有変数のアクセスの同期を取る命令です。
critical
criticalは下にに続くブロック({ }で囲まれた範囲)をアトミック処理します。
// ★「sum = 1 + 2 + 3 + ... + 100」を式で表現
//
// 1 + 100 = 101
// 2 + 99 = 101
// 3 + 98 = 101 --> 100個
// :
// 100 + 1 = 101
//
// 答え sum = (1 + 100) * 100 / 2 = 5050
bool logflag = true;
int value = 100;
int sum = 0;
#pragma omp parallel for firstprivate(logflag)
for(int i = 1; i <= value; i++) {
if (logflag) {
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
logflag = false;
}
#pragma omp critical
{
sum += i; // アトミック処理対象のブロック
}
}
__android_log_print(ANDROID_LOG_INFO, "openmpSample", "Sum = %2d", sum);
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (2) i = 51 .../com.example.nativecode.openmp I/openmpSample: (0) i = 1 .../com.example.nativecode.openmp I/openmpSample: (3) i = 76 .../com.example.nativecode.openmp I/openmpSample: (1) i = 26 .../com.example.nativecode.openmp I/openmpSample: Sum = 5050
atomic
atmicは下に続く命令文をアトミック処理します。
// ★「sum = 1 + 2 + 3 + ... + 100」を式で表現
//
// 1 + 100 = 101
// 2 + 99 = 101
// 3 + 98 = 101 --> 100個
// :
// 100 + 1 = 101
//
// 答え sum = (1 + 100) * 100 / 2 = 5050
bool logflag = true;
int value = 100;
int sum = 0;
#pragma omp parallel for firstprivate(logflag)
for(int i = 1; i <= value; i++) {
if (logflag) {
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
logflag = false;
}
#pragma omp atomic
sum += i; // アトミック処理対象の命令
}
__android_log_print(ANDROID_LOG_INFO, "openmpSample", "Sum = %2d", sum);
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (1) i = 26 .../com.example.nativecode.openmp I/openmpSample: (2) i = 51 .../com.example.nativecode.openmp I/openmpSample: (0) i = 1 .../com.example.nativecode.openmp I/openmpSample: (3) i = 76 .../com.example.nativecode.openmp I/openmpSample: Sum = 5050
reduction
reductionはfor文によるリダクション演算をアトミック処理します。
// ★「sum = 1 + 2 + 3 + ... + 100」を式で表現
//
// 1 + 100 = 101
// 2 + 99 = 101
// 3 + 98 = 101 --> 100個
// :
// 100 + 1 = 101
//
// 答え sum = (1 + 100) * 100 / 2 = 5050
bool logflag = true;
int value = 100;
int sum = 0;
#pragma omp parallel for reduction(+:sum),firstprivate(logflag)
for(int i = 1; i <= value; i++) {
if (logflag) {
__android_log_print(ANDROID_LOG_INFO,
"openmpSample", "(%d) i = %2d", omp_get_thread_num(), i);
logflag = false;
}
sum += i; // リダクションの演算
}
__android_log_print(ANDROID_LOG_INFO, "openmpSample", "Sum = %2d", sum);
.../com.example.nativecode.openmp I/openmpSample: Total thread = 4 .../com.example.nativecode.openmp I/openmpSample: (0) i = 1 .../com.example.nativecode.openmp I/openmpSample: (2) i = 51 .../com.example.nativecode.openmp I/openmpSample: (3) i = 76 .../com.example.nativecode.openmp I/openmpSample: (1) i = 26 .../com.example.nativecode.openmp I/openmpSample: Sum = 5050
reductionは図に示したような処理構造に置き換えると考えられます。
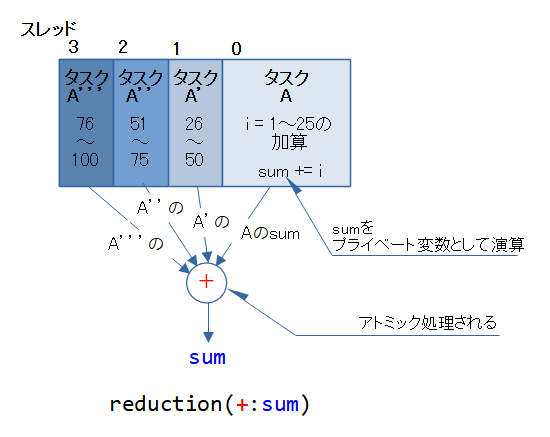
例えば、合計sumはリダクション演算で求められます。
int sum;
int a[4] = {1, 2, 3, 4};
sum = a[0] + a[1] + a[2] + a[3]; // +で配列aをリダクション演算
リダクション演算をfor文で表すと次のようになります。
int sum;
int a[4] = {1, 2, 3, 4};
for(int i = 0; i < 4; i++) { // +で配列aをリダクション演算
sum += a[i];
}
処理速度の違い
critical・atomic・reductionはどれも共有変数のアクセスの同期を取る命令です。
同じアトミック処理を行わせた場合であっても、処理速度に違いがでます。
| 処理速度 | 宣言句 | アトミック処理の範囲 |
|---|---|---|
| 速い 遅い | reduction | 演算子 |
| atomic | 命令文 | |
| critical | ブロック |
範囲が広ければアトミック処理は複雑になり、処理速度が遅くなります。
OpenMPによるマルチスレッド化の例
例として、以前作成したmonoFilter(参照:Nativeコード(NDK)でBitmapの画像処理)関数をOpenMPでマルチスレッド化してみました。
記述は至って簡単です。「parallel for」命令を一行追加するだけです。
#include <jni.h>
#include <string>
#include <android/bitmap.h>
typedef struct {
uint8_t red;
uint8_t green;
uint8_t blue;
uint8_t alpha;
} rgba;
extern "C" JNIEXPORT jobject JNICALL
Java_com_example_nativecode_graphics_MainActivity_monoFilter(
JNIEnv* env,
jobject obj,
jobject jbitmap) {
int result;
AndroidBitmapInfo info;
result = AndroidBitmap_getInfo(env, jbitmap, &info);
if(result < 0) return NULL;
if(info.format != ANDROID_BITMAP_FORMAT_RGBA_8888) return NULL;
void *pixels;
result = AndroidBitmap_lockPixels(env, jbitmap, &pixels);
if(result < 0) return NULL;
#pragma omp parallel for
for(int y = 0; y < info.height; y++) {
rgba *line = (rgba *)((uint8_t *)pixels + info.stride * y);
for(int x = 0; x < info.width; x++) {
float mono =0.299f * (float)line[x].red
+ 0.587f * (float)line[x].green
+ 0.114f * (float)line[x].blue;
line[x].red = (uint8_t)mono;
line[x].green = (uint8_t)mono;
line[x].blue = (uint8_t)mono;
}
}
AndroidBitmap_unlockPixels(env, jbitmap);
return jbitmap;
}
これにより、ラインを走査するfor文が分割されて、複数のスレッドで処理されます。
この例は、各スレッドのアクセスするメモリーが独立しているので、アクセスの競合が発生しません。なので、マルチスレッド化が容易なのです。
高速化の効果は絶大でした。
| OpenMPなし シングルコア | OpenMPあり ダブルコア | OpenMPあり クアッドコア |
|
|---|---|---|---|
| 処理時間[ms] | 115 (1.00) | 72 (0.63) | 42 (0.37) |
| 画像サイズ:4800 x 3600、ホストCPU:Core i7-2600、デバイス:AVD(api24) | |||
関連記事: